
こんにちは!cumoです。
タイトル通りですが、私自身joinを使う際に「how」の動作イメージがすぐに思い浮かばず、困ることが多々ありました。そのため、各処理についてここにまとめておこうと思い立ちました!
今回はpolarsを例に作成しましたが、pandasともほぼ同じ動作となるため、出力される表のイメージとして理解の助けになるのではと思っています。
私と同じく「how」の動作に不安がある人の参考になれば幸いです。
目次:
- その1:pl.joinがもつ引数
- その2:「how」の取り得る値
- その3:実際にコードを動かして確認
- Inner
- Left
- Right
- Full
- Cross
- Semi
- Anti
- まとめ
その1:pl.joinがもつ引数
pl.joinはデータフレーム(pl.DataFrame)同士を結合するメソッドです。
次の表が取り得る引数とその引数の役割を簡単にまとめたものです。詳しくは公式ドキュメントを参照。

| 引数 | 役割 |
| other | 結合したいDataFrame |
| on | 両方のDataFramesの結合カラムの名前(複数可) |
| how | 結合方法(今回詳細説明する引数) |
| left_on | 左結合させたいカラム名 |
| right_on | 右結合させたいカラム名 |
| suffix | 名前が重複するカラムに付加する接尾語 |
| joun_nulls | Null値で結合 |
| coalesce | Null値と同じ行列を参照して置き換え |
その2:「how」の取り得る値
howが持つ結合方法は次の様になっています。
- inner:両方のテーブルで値が一致する行を返す
- left:左のテーブルからすべての行を、右のテーブルからマッチした行を返す
- right:右のテーブルのすべての行と、左のテーブルのマッチした行を返す
- full:左テーブルまたは右テーブルのいずれかにマッチする行がある場合、すべての行を返す
- cross:両テーブルの行のデカルト積を返す
- semi:左のテーブルから、右のテーブルと一致する行を返す
- anti:左のテーブルから、右のテーブルにマッチしない行を返す
ここでは言葉でまとめていますが、いまいちイメージしづらいので実際にコードを動かして確認していきます。
その3:実際にコードを動かして確認
今回はコードにあるような模擬的なテーブルを2つ用意して動作を確認していきます。
一つは「名前、年齢、職業、給料」のカラムをもつ4行のデータフレーム(以降df1とします)
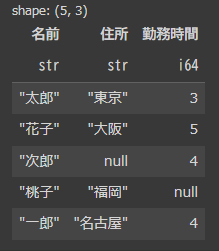
もう一つは「名前、住所、勤務時間」のカラムをもち、欠損値をもつ5行のデータフレーム(以降df2とします)です。
このdf1に結合方法を変えつつ、df2を結合させることで出力される表の違いを確認していきます。
実行環境はGoogle Colaboratoryを使用しました。
import polars as pl
# データフレームを作成
data1 = {
"名前": ["太郎", "花子", "桃子", "健太"],
"年齢": [25, 30, 22, 28],
"職業": ["エンジニア", "デザイナー", "マネージャー", "アナリスト"],
"給料": [5000000, 5500000, 4500000, 4800000]
}
df1 = pl.DataFrame(data1)
display(df1)
data2 = {
"名前": ["太郎", "花子", "次郎", "桃子", "一郎"],
"住所": ["東京", "大阪", None, "福岡", "名古屋"],
"勤務時間": [3, 5, 4, None, 4]
}
df2 = pl.DataFrame(data2)
display(df2)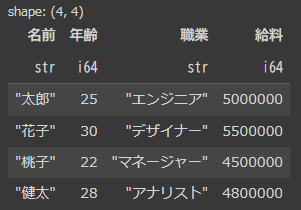
Inner
df1に対してdf2を「how=”inner”」で結合してみます。このときkeyは”名前”で結合します。
df_inner_join = df1.join(df2, on="名前", how="inner")
display(df_inner_join)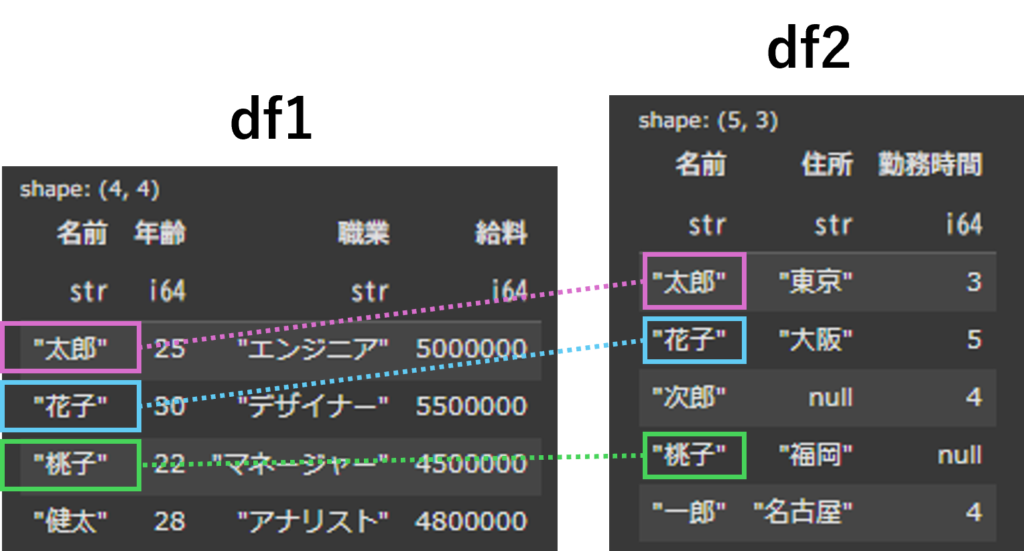
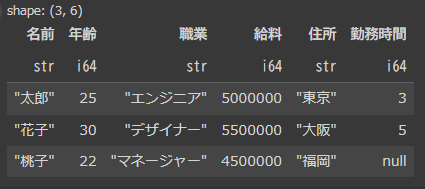
df1とdf2の両方にある”名前”だけを参照して結合されています。
そのため、df1にしかいない”健太”とdf2にしかいない”一郎”と“次郎”の行は消えてしまいます。
Left
df1に対してdf2を「how=”left”」で結合してみます。このときkeyは”名前”で結合します。
df_left_join = df1.join(df2, on="名前", how="left")
display(df_left_join)
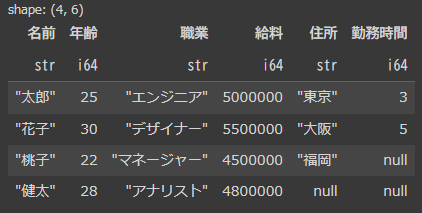
df1(左側)にある”名前”だけを参照して結合されています。
そのため、df2にしかいない“一郎”と“次郎”の行は消え、df2にはいない“健太”の“住所”と“勤務時間“はnull埋めになります。
Right
df1に対してdf2を「how=”right”」で結合してみます。このときkeyは”名前”で結合します。
df_right_join = df1.join(df2, on="名前", how="right")
display(df_right_join)
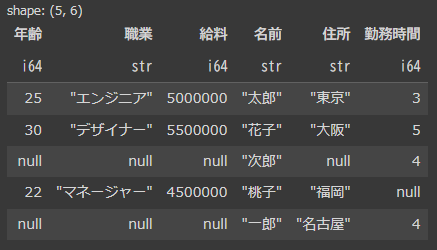
df2(右側)にある”名前”だけを参照して結合されています。
そのため、df2にはいない“健太”は消えてしまい、df1にはいない“次郎”と“一郎”の“年齢”と“職業”と“給料“はnull埋めになります。
また、右結合は右側のデータフレームのkeyを参照してそのまま結合するため、並び順に違和感があります。
Full
df1に対してdf2を「how=”full”」で結合してみます。このときkeyは”名前”で結合します。
df_full_join = df1.join(df2, on="名前", how="full")
display(df_full_join)
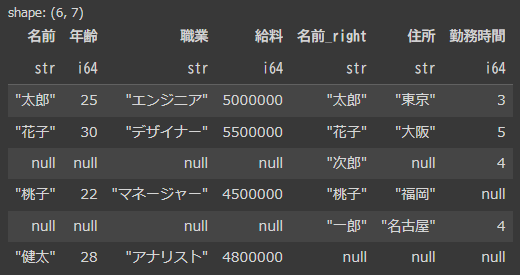
df1(左側)にある”名前”を参照して全て結合されています。
そのため、df1にはいない”一郎”と“次郎”の“年齢”、“職業”、“給料“はnull埋めとなります。また、df2にはいない“健太”の“住所”と“勤務時間”はnull埋めになってます。
Cross
df1に対してdf2を「how=”cross”」で結合してみます。cross joinは各行を全ての組み合わせでjoinさせるため、keyは不要です。
df_cross_join = df1.join(df2, how="cross")
display(df_cross_join)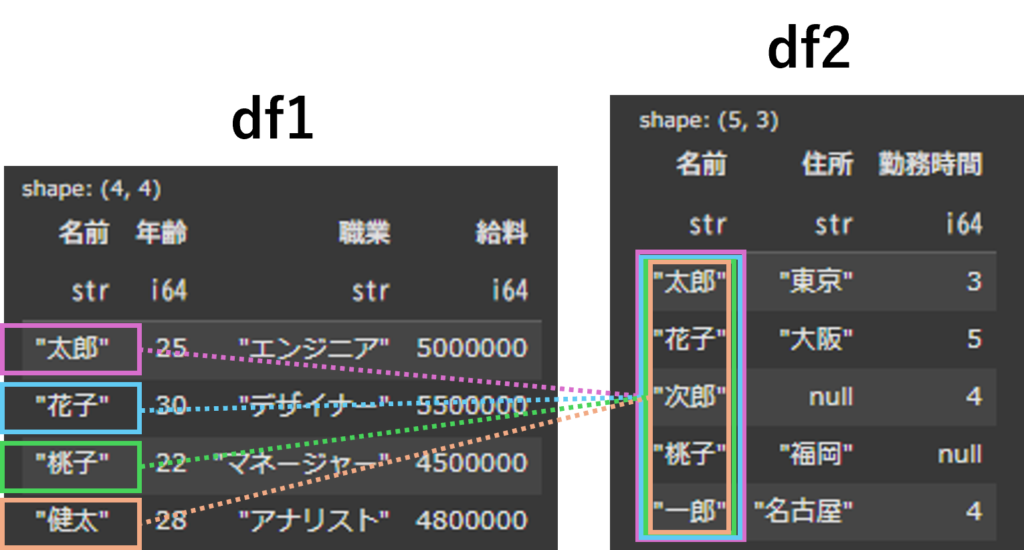
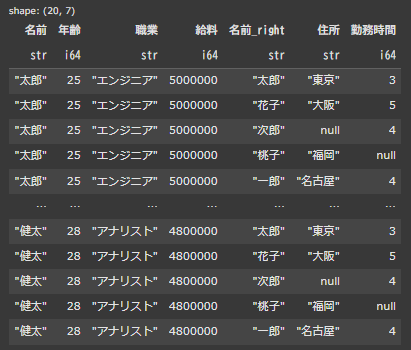
df1(左側)にある”名前”に対してdf2の行全てが結合されています。
df1とdf2で共通してもっている”名前”カラムは、二重になってしまうため、df2の方の”名前”カラムが自動的に”名前_right”とというカラム名に変更されています。
cross joinを行うことで、df1とdf2の行の全ての組み合わせの行が作成されます。今回の例でいうと、df1の5行×df2の4行=20行の結果が帰ってきます。
Semi
df1に対してdf2を「how=”semi”」で結合してみます。このときもkeyは”名前”で結合します。
df_semi_join = df1.join(df2, on="名前", how="semi")
display(df_semi_join)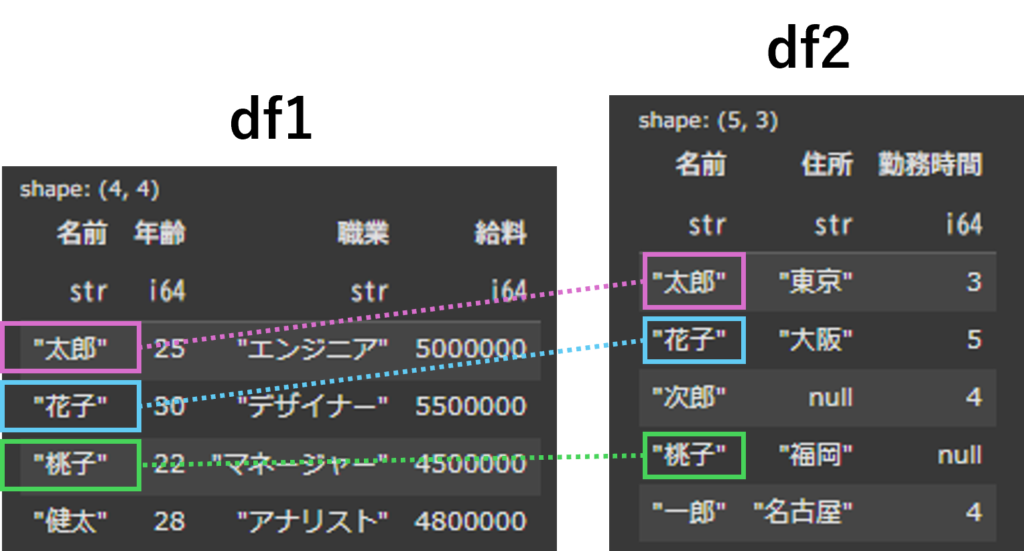
df1(左側)とdf2(右側)の”名前”カラムを参照して、共通している行だけを出力しています。
他のjoin方法と異なるのが、今回は直接的に結合はしておらず、df2の”名前”カラムと一致しているかどうかを確認して、一致するdf1だけを出力する点です。
この結合方法は2つのデータの重複確認に非常に有効な方法として使われます。
Anti
df1に対してdf2を「how=”anti”」で結合してみます。このときkeyは”名前”で結合します。
df_anti_join = df1.join(df2, on="名前", how="anti")
display(df_anti_join)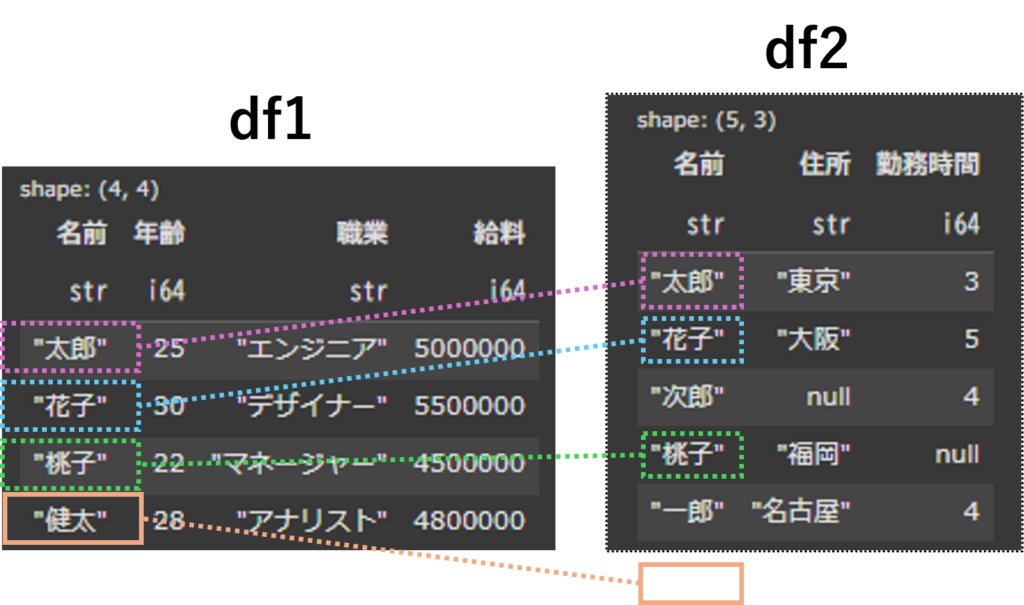
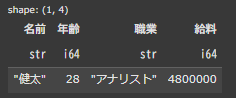
df1(左側)とdf2(右側)の”名前”カラムを参照して、df1にだけしか存在していない行だけを出力しています。
semi joinとは逆の動作となり、今回も直接的に結合はしておらず、df2の”名前”カラムと一致しているかどうかを確認して、一致していないdf1行だけを出力します。
これも重複を確認後、一致していない行の確認に役立ちます。
まとめ
以上がhowの方法の紹介でした。
個人的には「smei join」や「anti join」はデータアセスメントを行う際に非常に有効な方法だと改めて確認できたのでよかったです!
表形式のデータを扱う際にhowの各手法をマスターすることでコードも短く書くことができそうです。
皆さんの参考になったら嬉しいです!最後まで読んでくださりありがとうございました!


コメント